我们将构建一个简单的应用程序,用来归档及显示微推文。我们可以把它想象成更大的应用程序中的一个组件,这个应用允许用户密切注意与其业务相关的搜索项。该示例将展示处理来自Twitter API之类数据源的JSON,以及将它转成MongoDB文档有多容易。如果使用关系型数据库,就不得不事先设计一个Schema,可能还会包含多张数据表,然后还要声明那些表。使用MongoDB的话,这些事情就都不需要了,但还能保留推文文档丰富的结构,并且可以高效地进行查询。
我们称该应用为TweetArchiver,它由两个组件组成:归档器和查看器,归档器会调用Twitter的搜索API保存相关推文,查看器用于在Web浏览器里浏览结果。
3.3.1 配置
该应用程序会用到三个Ruby库,可以这样进行安装:
gem install mongo gem install twitter gem install sinatra
有个配置文件能在归档器和查看器脚本之间进行共享会很有用,创建一个名为config.rb的文件,初始化如下常量:
DATABASE_NAME = \"twitter-archive\" COLLECTION_NAME = \"tweets\" TAGS = [\"mongodb\", \"ruby\"]
首先指定了应用程序中使用的数据库和集合的名字。然后定义了一个搜索项数组,我们会把它们发给Twitter API。
接下来是编写归档器脚本。先从TweetArchiver类开始,用一个搜索项来进行实例化。然后调用TweetArchiver实例的update方法,这会发起一次Twitter API调用,将结果保存到MongoDB集合里。
让我们先从类的构造器下手:
def initialize(tag) connection = Mongo::Connection.new db = connection[DATABASE_NAME] @tweets = db[COLLECTION_NAME] @tweets.create_index([[\'id\', 1]], :unique => true) @tweets.create_index([[\'tags\', 1], [\'id\', -1]]) @tag = tag @tweets_found = 0 end
initialize方法实例化了一个连接、一个数据库对象和用来存储推文的集合对象,其中还创建了两个索引。每条推文都有一个id字段(与MongoDB的_id字段不同),代表推文的内部Twitter ID。我们为这个字段创建了一个唯一性索引,以避免同一条推文被插入两次。
我们还在tags和id字段上创建了一个组合索引,tags升序,id降序。索引可以指定是升序还是降序,这主要在创建组合索引时比较重要,应该总是基于自己期待的查询模式来选择方向。因为我们希望查询特定的标签,并且按时间由近及远显示结果,所以tags升序、id降序的索引既能用来过滤结果,也能用来进行排序。如你所见,可以用1表示升序、-1表示降序,以此来指明索引方向。
3.3.2 收集数据
在MongoDB中可以插入数据而无需考虑其结构。因为不用事先知道会有哪些字段,Twitter可以随意修改API的返回值,不会给应用程序带来什么不良后果。一般来说,如果使用RDBMS,对Twitter API(说得更广泛点,对数据源)的任何改动都会要求进行数据库Schema迁移。用了MongoDB,应用程序可能需要做些修改来适应新的数据Schema,但数据库本身可以自动处理各种文档风格的Schema。
Ruby的Twitter库返回的是Ruby散列,因此可以直接将其传递给MongoDB集合对象。在TweetArchiver中,添加如下实例方法:
def save_tweets_for(term)
Twitter::Search.new.containing(term).each do |tweet|
@tweets_found += 1
tweet_with_tag = tweet.to_hash.merge!({\"tags\" => [term]})
@tweets.save(tweet_with_tag)
end
end
在保存每个推文文档前,要做个小修改。为了简化日后的查询,将搜索项添加到tags属性中。然后将修改过的文档传递给save方法。代码清单3-1中是完整的归档器代码。
代码清单3-1 抓取推文并将其归档在MongoDB中的类
require \'rubygems\'
require \'mongo\'
require \'twitter\'
require File.join{File.dirname(__FILE),\'config\';
class TweetArchiver
# Create a new instance of TweetArchiver
def initialize(tag)
connection = Mongo::Connection.new
db = connection[DATABASE_NAME]
@tweets = db[COLLECTION_NAME]
@tweets.create_index([[\'id\', 1]], :unique => true)
@tweets.create_index([[\'tags\', 1], [\'id\', -1]])
@tag = tag
@tweets_found = 0
end
def update
puts \"Starting Twitter search for \'#{@tag}\'...\"
save_tweets_for(@tag)
print \"#{@tweets_found} tweets saved.nn\"
end
private
def save_tweets_for(term)
Twitter::Search.new(term).each do |tweet|
@tweets_found += 1
tweet_with_tag = tweet.to_hash.merge!({\"tags\" => [term]})
@tweets.save(tweet_with_tag)
end
end
end
剩下的就是要编写一个脚本,为每个搜索项运行TweetArchiver代码。创建update.rb,包含以下代码:
require \'config\' require \'archiver\' TAGS.each do |tag| archive = TweetArchiver.new(tag) archive.update end
然后,运行该更新脚本:
ruby update.rb
我们会看到一些状态消息,它们指明程序找到并保存了推文。可以打开MongoDB Shell,直接查询集合来验证脚本是否能正常运行:
> use twitter-archive switched to db twitter-archive > db.tweets.count 30
为了保证归档内容始终是最新的,可以使用一个cron任务,每隔几分钟就运行一次更新脚本。但那是管理的细节,这里的重点是通过寥寥几行代码就能保存从Twitter查到的推文。1接下来的任务是显示结果。
1. 还可以用更少的代码来实现这一功能,这就留给读者作为练习了。
3.3.3 查看归档
我们将使用Ruby的Sinatra Web框架构建一个简单的应用,用来显示结果。创建一个名为viewer.rb的文件,和其他脚本放在同一目录里。随后,新建views子目录,放入一个名为tweets.erb的文件。项目结构看起来应该像下面这样:
- config.rb - archiver.rb - update.rb - viewer.rb - /views - tweets.erb
现在编辑viewer.rb,加入以下代码。
代码清单3-2 一个简单的Sinatra应用程序,用于显示并搜索Tweet归档

前面几行代码加载了所需的库,还有配置文件➊。接下来的配置块中创建了一个到MongoDB的连接,并把指向tweets集合的引用保存在常量TWEETS里➋。
应用程序中最重要的部分是get \'/\' do之后的代码,这个块里的代码处理了对应用程序根URL的请求。首先,构建查询选择器:如果提供了URL参数tags则创建一个查询选择器,将结果集限定在给定标签里➌;否则就创建一个空白的选择器,查询会返回集合中的全部文档➍。然后发起查询➎。现在你应该知道赋给@tweets变量的不是结果集,而是一个游标,我们将在视图中对该游标进行迭代。
最后一行➏呈现了视图文件tweets.erb,完整代码如代码清单3-3所示。
代码清单3-3 用于显示推文的内嵌Ruby的HTML
<!DOCTYPE html PUBLIC \"-//W3C//DTD XHTML 1.0 Transitional//EN\"
\"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd\">
<html lang=\'en\' xml:lang=\'en\' xmlns=\'http://www.w3.org/1999/xhtml\'>
<head>
<meta http-equiv=\"Content-Type\" content=\"text/html; charset=UTF-8\"/>
<style>
body {
background-color: #DBD4C2;
width: 1000px;
margin: 50px auto;
}
h2 {
margin-top: 2em;
}
</style>
</head>
<body>
<h1>Tweet Archive
<% TAGS.each do |tag| %>
<a href=\"/?tag=<%= tag %>\"><%= tag %>
<% end %>
<% @tweets.each do |tweet| %>
<h2><%= tweet[\'text\'] %>
<p>
<a href=\"http://twitter.com/<%= tweet[\'from_user\'] %>\">
<%= tweet[\'from_user\'] %>
</a>
on <%= tweet[\'created_at\'] %>
</p>
<img src=\"<%= tweet[\'profile_image_url\'] %>\" />
<% end %>
</body>
</html>
大部分代码只是混入了ERB的HTML,2其中的重要部分在结尾附近,有两个迭代器。第一个迭代器遍历了标签列表,显示的链接能将结果集限定在指定的标签上。@tweets.each开头的是第二个迭代器,遍历了每条推文,显示推文的正文、创建日期和用户头像图片。运行应用程序来查看结果:
2. ERB全称是embedded Ruby。Sinatra应用通过一个ERB处理器来运行tweets.erb文件,并在应用程序上下文中运算<%和%>之间的Ruby代码。
$ ruby viewer.rb
如果应用程序正常启动,我们将看到标准的Sinatra启动消息:
$ ruby viewer.rb == Sinatra/1.0.0 has taken the stage on 4567 for development with backup from Mongrel
我们可以打开Web浏览器,访问http://localhost:4567,页面应该会和图3-3类似。单击屏幕上方的链接可以缩小结果范围,基于特定的标签显示结果。
应用程序就这样完成了,不可否认它比较简单,但它演示了MongoDB的易用性。我们不用事先定义Schema;能充分利用二级索引加速查询,避免重复插入;还能相对简单地和编程语言进行集成。
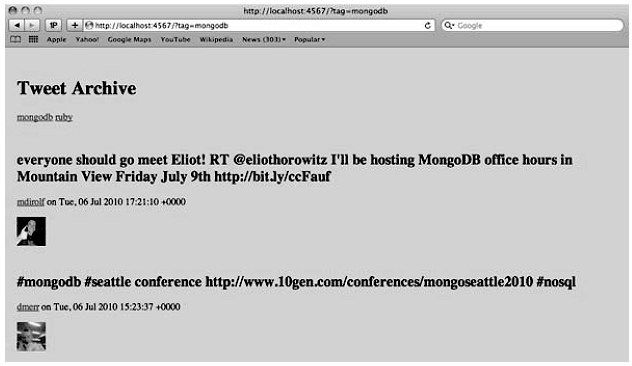
图3-3 Web浏览器中呈现的推文归档