第4章介绍过一个文本分类算法:朴素贝叶斯。该算法将文本文档看做是词汇空间里的向量。第6章又介绍了效果很好的SVM分类算法,该算法将每个文档看做是成千上万个特征组成的向量。
在机器学习领域,海量文档上做文本分类面临很大的挑战。怎样在如此大的数据上训练分类器呢?如果能将算法分成并行的子任务,那么MapReduce框架有望帮我们实现这一点。回忆第6章,SMO算法一次优化两个支持向量,并在整个数据集上迭代,在需要注意的值上停止。该算法看上去并不容易并行化。
在MapReduce框架上使用SVM的一般方法
- 收集数据:数据按文本格式存放。
- 准备数据:输入数据已经是可用的格式,所以不需任何准备工作。如果你需要解析一个大规模的数据集,建议使用map作业来完成,从而达到并行处理的目的。
- 分析数据:无。
- 训练算法:与普通的SVM一样,在分类器训练上仍需花费大量的时间。
- 测试算法:在二维空间上可视化之后,观察超平面,判断算法是否有效。
- 使用算法:本例不会展示一个完整的应用,但会展示如何在大数据集上训练SVM。该算法其中一个应用场景就是文本分类,通常在文本分类里可能有大量的文档和成千上万的特征。
SMO算法的一个替代品是Pegasos算法,后者可以很容易地写成MapReduce的形式。本节将分析Pegasos算法,介绍如何写出分布式版本的Pegasos算法,最后在mrjob中运行该算法。
15.6.1 Pegasos算法
Pegasos是指原始估计梯度求解器(Primal Estimated sub-GrAdient Solver)。该算法使用某种形式的随机梯度下降方法来解决SVM所定义的优化问题,研究表明该算法所需的迭代次数取决于用户所期望的精确度而不是数据集的大小,有关细节可以参考原文1。原文有长文和短文两个版本,推荐阅读长文。
1. S. Shalev-Shwartz, Y. Singer, N. Srebro, “Pegasos: Primal Estimated sub-GrAdient SOlver for SVM,”Proceed- ings of the 24th International Conference on Machine Learning 2007.
第6章提到,SVM算法的目的是找到一个分类超平面。在二维情况下也就是要找到一条直线,将两类数据分隔开来。Pegasos算法工作流程是:从训练集中随机挑选一些样本点添加到待处理列表中,之后按序判断每个样本点是否被正确分类;如果是则忽略,如果不是则将其加入到待更新集合。批处理完毕后,权重向量按照这些错分的样本进行更新。整个算法循环执行。
上述算法伪代码如下:
将w初始化为0
对每次批处理
随机选择k个样本点(向量)
对每个向量
如果该向量被错分:
更新权重向量w
累加对w的更新
为了解实际效果,Python版本的实现见程序清单15-4。
程序清单15-4 SVM的Pegasos算法
def predict(w, x):
return w*x.T
def batchPegasos(dataSet, labels, lam, T, k):
m,n = shape(dataSet); w = zeros(n);
dataIndex = range(m)
for t in range(1, T+1):
wDelta = mat(zeros(n))
eta = 1.0/(lam*t)
random.shuffle(dataIndex)
for j in range(k):
i = dataIndex[j]
p = predict(w, dataSet[i,:])
if labels[i]*p < 1:
wDelta += labels[i]*dataSet[i,:].A
w = (1.0 - 1/t)*w + (eta/k)*wDelta
return w
代码注释翻译为: 1:将待更新值累加
程序清单15-4的代码是Pegasos算法的串行版本。输入值T和k分别设定了迭代次数和待处理列表的大小。在T次迭代过程中,每次需要重新计算eta。它是学习率,代表了权重调整幅度的大小。在外循环中,需要选择另一批样本进行下一次批处理;在内循环中执行批处理,将分类错误的值全部累加之后更新权重向量❶。
如果想试试它的效果,可以用第6章的数据来运行本例程序。本书不会对该代码做过多分析,它只为Pegasos算法的MapReduce版本做一个铺垫。下节将在mrjob中建立并运行一个MapReduce版本的Pegasos算法。
15.6.2 训练算法:用mrjob实现MapReduce版本的SVM
本节将用MapReduce来实现程序清单15-4的Pegasos算法,之后再用15.5节讨论的mrjob框架运行该算法。首先要明白如何将该算法划分成map阶段和reduce阶段,确认哪些可以并行,哪些不能并行。
对程序清单15-4的代码运行情况稍作观察将会发现,大量的时间花费在内积计算上。另外,内积运算可以并行,但创建新的权重变量w是不能并行的。这就是将算法改写为MapReduce作业的一个切入点。在编写mapper和reducer的代码之前,先完成一部分外围代码。打开文本编辑器,创建一个新文件mrSVM.py,然后在该文件中添加下面程序清单的代码。
程序清单15-5 mrjob中分布式Pegasos算法的外围代码
from mrjob.job import MRJob
import pickle
from numpy import *
class MRsvm(MRJob):
DEFAULT_INPUT_PROTOCOL = \'json_value\'
def __init__(self, *args, **kwargs):
super(MRsvm, self).__init__(*args, **kwargs)
self.data = pickle.load(open(\'<path to your Ch15 code directory>svmDat27\'))
self.w = 0
self.eta = 0.69
self.dataList =
self.k = self.options.batchsize
self.numMappers = 1
self.t = 1
def configure_options(self):
super(MRsvm, self).configure_options
self.add_passthrough_option(\'--iterations\', dest=\'iterations\', default=2, type=\'int\',help=\'T: number of iterations to run\')
self.add_passthrough_option(\'--batchsize\', dest=\'batchsize\', default=100, type=\'int\',help=\'k: number of data points in a batch\')
def steps(self):
return ([self.mr(mapper=self.map, mapper_final=self.map_fin,reducer=self.reduce)]*self.options.iterations)
if __name__ == \'__main__\':
MRsvm.run
程序清单15-5的代码进行了一些设定,从而保证了map和reduce阶段的正确执行。在程序开头,Mrjob、NumPy和Pickle模块分别通过一条include语句导入。之后创建了一个mrjob类MRsvm,其中__init__方法初始化了一些在map和reduce阶段用到的变量。Python的模块Pickle在加载不同版本的Python文件时会出现问题。为此,我将Python2.6和2.7两个版本对应的数据文件各自存为svmDat26和svmDat27。
对应于命令行输入的参数,Configure_options方法建立了一些变量,包括迭代次数(T)、待处理列表的大小(k)。这些参数都是可选的,如果未指定,它们将采用默认值。
最后,steps方法告诉mrjob应该做什么,以什么顺序来做。它创建了一个Python的列表,包含map、map_fin和reduce这几个步骤,然后将该列表乘以迭代次数,即在每次迭代中重复调用这个列表。为了保证作业里的任务链能正确执行,mapper需要能够正确读取reducer输出的数据。单个MapReduce作业中无须考虑这个因素,这里需要特别注意输入和输出格式的对应。
我们对输入和输出格式进行如下规定:

传入的值是列表数组,valueList的第一个元素是一个字符串,用于表示列表的后面存放的是什么类型的数据,例如{‘x’,23}和[‘w’,[1,5,6]]。每个mapper_final都将输出同样的key,这是为了保证所有的key/value对都输出给同一个reducer。
定义好了输入和输出之后,下面开始写mapper和reducer方法,打开mrSVM.py文件并在MRsvm类中添加下面的代码。
程序清单15-6 分布式Pegasos算法的mapper和reducer代码
def map(self, mapperId, inVals):
if False: yield
if inVals[0]==\'w\':
self.w = inVals[1]
elif inVals[0]==\'x\':
self.dataList.append(inVals[1])
elif inVals[0]==\'t\': self.t = inVals[1]
def map_fin(self):
labels = self.data[:,-1]; X=self.data[:,0:-1]
if self.w == 0: self.w = [0.001]*shape(X)[1]
for index in self.dataList:
p = mat(self.w)*X[index,:].T
if labels[index]*p < 1.0:
yield (1, [\'u\', index])
yield (1, [\'w\', self.w])
yield (1, [\'t\', self.t])
def reduce(self, _, packedVals):
for valArr in packedVals:
if valArr[0]==\'u\': self.dataList.append(valArr[1])
elif valArr[0]==\'w\': self.w = valArr[1]
elif valArr[0]==\'t\': self.t = valArr[1]
labels = self.data[:,-1]; X=self.data[:,0:-1]
wMat = mat(self.w); wDelta = mat(zeros(len(self.w)))
for index in self.dataList:
#❶ 将更新值累加
wDelta += float(labels[index])*X[index,:]
eta = 1.0/(2.0*self.t)
wMat = (1.0 - 1.0/self.t)*wMat + (eta/self.k)*wDelta
for mapperNum in range(1,self.numMappers+1):
yield (mapperNum, [\'w\', wMat.tolist[0] ])
if self.t < self.options.iterations:
yield (mapperNum, [\'t\', self.t+1])
for j in range(self.k/self.numMappers):
yield (mapperNum, [\'x\',random.randint(shape(self.data)[0]) ])
程序清单15-6里的第一个方法是map,这也是分布式的部分,它得到输入值并存储,以便在map_fin中处理。该方法支持三种类型的输入:w向量、t或者x。t是迭代次数,在本方法中不参与运算。状态不能保存,因此如果需要在每次迭代时保存任何变量并留给下一次迭代,可以使用key/value对传递该值,抑或是将其保存在磁盘上。显然前者更容易实现,速度也更快。
map_fin方法在所有输入到达后开始执行。这时已经获得了权重向量w和本次批处理中的一组x值。每个x值是一个整数,它并不是数据本身,而是索引。数据存储在磁盘上,当脚本执行的时候读入到内存中。当map_fin启动时,它首先将数据分成标签和数据,然后在本次批处理的数据(存储在self.dataList里)上进行迭代,如果有任何值被错分就将其输出给reducer。为了在mapper和reducer之间保存状态,w向量和t值都应被发送给reducer。
最后是reduce函数,对应本例只有一个reducer执行。该函数首先迭代所有的key/value对并将值解包到一个局部变量datalist里。之后dataList里的值都将用于更新权重向量w,更新量在wDelta中完成累加❶。然后,wMat按照wDelta和学习率eta进行更新。在wMat更新完毕后,又可以重新开始整个过程:一个新的批处理过程开始,随机选择一组向量并输出。注意,这些向量的key是mapper编号。
为了看一下该算法的执行效果,还需要用一些类似于reducer输出的数据作为输入数据启动该任务,我为此附上了一个文件kickStart.txt。在本机上执行前面的代码可以用下面的命令:
%python mrSVM.py < kickStart.txt
.
.
.
streaming final output from c:userspeterappdatalocaltemp
mrSVM.Peter.20110301.011916.373000outputpart-00000
1 [\"w\", [0.51349820499999987, -0.084934502500000009]]
removing tmp directory c:userspeterappdatalocaltemp
mrSVM.Peter.20110301.011916.373000
这样就输出了结果。经过2次和50次迭代后的分类面如图15-9所示。
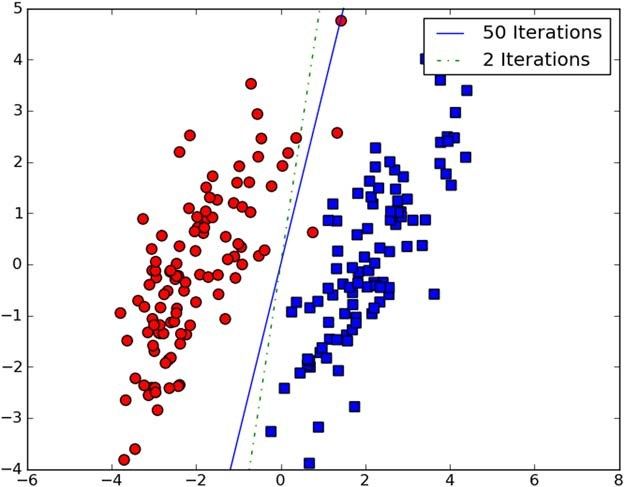
图15-9 经过多次迭代的分布式Pegasos算法执行结果。该算法收敛迅速,多次迭代后可以得到更好的结果
如果想在EMR上运行该任务,可以添加运行参数:-r emr。该作业默认使用的服务器个数是1。如果要调整的话,添加运行参数:--num-ec2-instances=2(这里的2也可以是其他正整数),整个命令如下:
%python mrSVM.py -r emr --num-ec2-instances=3 < kickStart.txt > myLog.txt
要查看所有可用的运行参数,输入%python mrSVM.py –h。
调试mrjob
调试一个mrjob脚本将比调试一个简单的Python脚本棘手得多。这里仅给出一些调试建议。
- 确保已经安装了所有所需的部件:boto、simplejson和可选的PyYAML。
- 可以在~/.mrjob.conf文件中设定一些参数,确定它们是正确的。
- 在将作业放在EMR上运行之前,尽可能在本地多做调试。能在花费10秒就发现一个错误的情况下,就不要花费10分钟才发现一个错误。
- 检查base_temp_dir目录,它在~/.mrjob.conf中设定。例如在我的机器上,该目录的存放位置是/scratch/$USER,其中可以看到作业的输入和输出,它将对程序的调试非常有帮助。
- 一次只运行一个步骤。
到现在为止,读者已经学习了如何编写以及如何在大量机器上运行机器学习作业,下节将分析这样做的必要性。